From 1,000 applicants to 3 finalists.
AI agents run the funnel — applications, resume scoring, auto-filter, proctored assessment, multi-dimensional scoring, ranked shortlist. You interview only the standouts.
Replace resume-only filtering and 5-hour panels with an AI-graded funnel that surfaces the candidates who actually build with AI — before you spend an hour interviewing.
The Problem
With VibeLevel
The Agentic Platform to Learn, Assess & Hire Smart.
You only interview candidates who’ve already proven they can build alongside AI.
Create a job post or assessment
Use pre-built templates or create custom assessments. Add an application form to collect candidates.
Customize AI agent & scoring
Configure the AI assistant persona, evaluation criteria, and scoring weights tailored to your role.
Let the agent do the grinding
Share one link. The funnel agent scores resumes, sends assessments, runs proctoring, and ranks — you watch results roll in.
Review, score & shortlist
AI-scored reports across multiple dimensions plus Human Contribution Score. Compare candidates side by side.
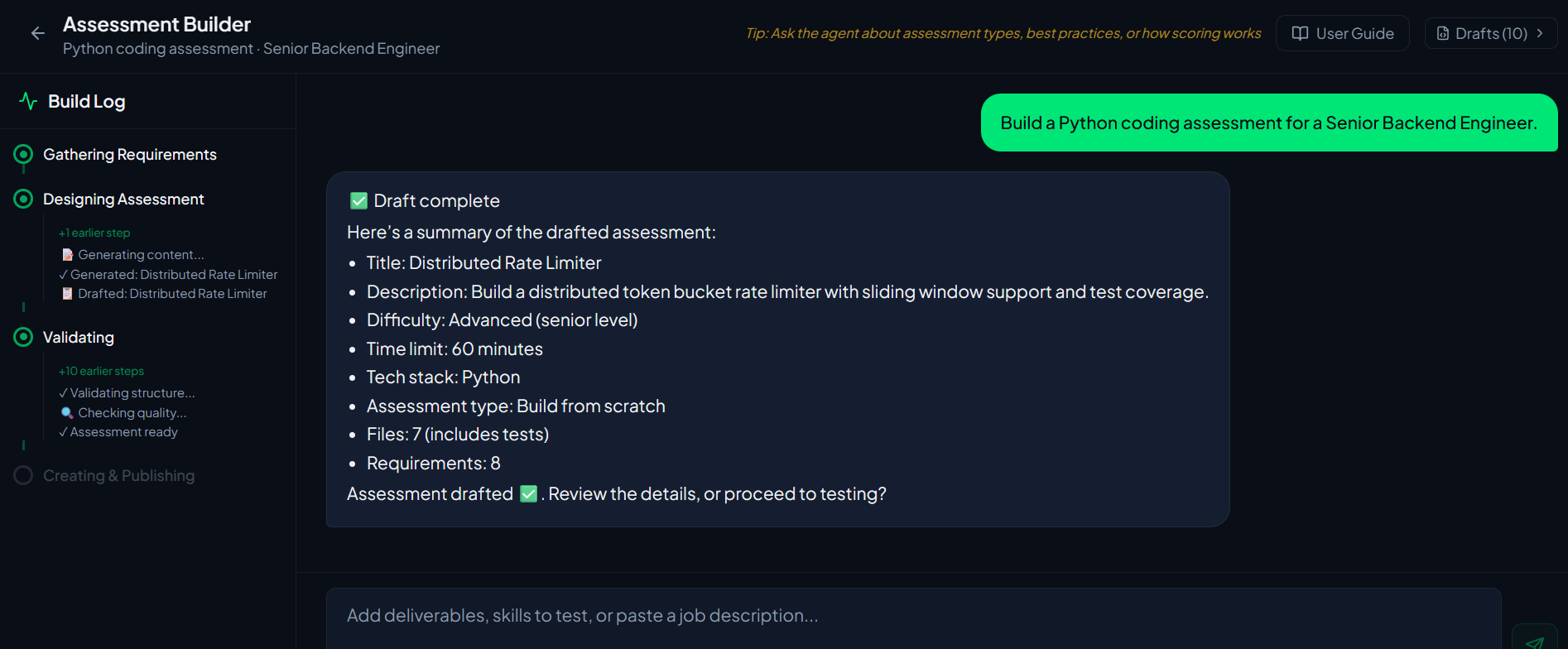
Chat your assessment into existence.
Describe the role, the rubric, and the constraints. The builder gathers requirements, designs the assessment, validates it in a live E2B sandbox, and publishes — no template wrangling.
Same engine. Every role.
Engineers, PMs, sales, support, analysts, ops — every role today works alongside AI. VibeLevel measures collaboration skill across all of them, on the same platform.
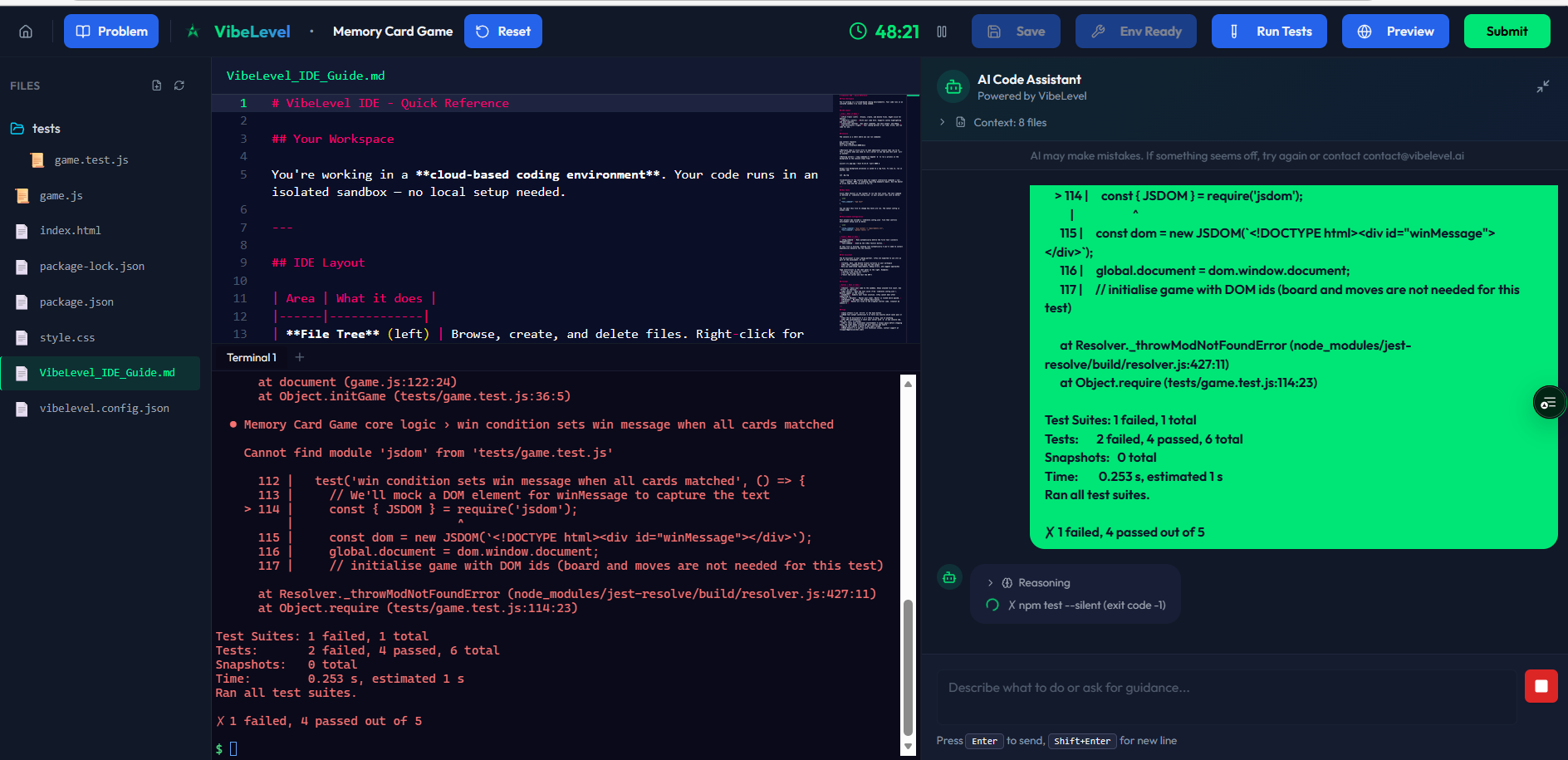
Build software with AI
Python · TypeScript · JavaScript · system design. Real IDE, real terminal, AI agent of choice.
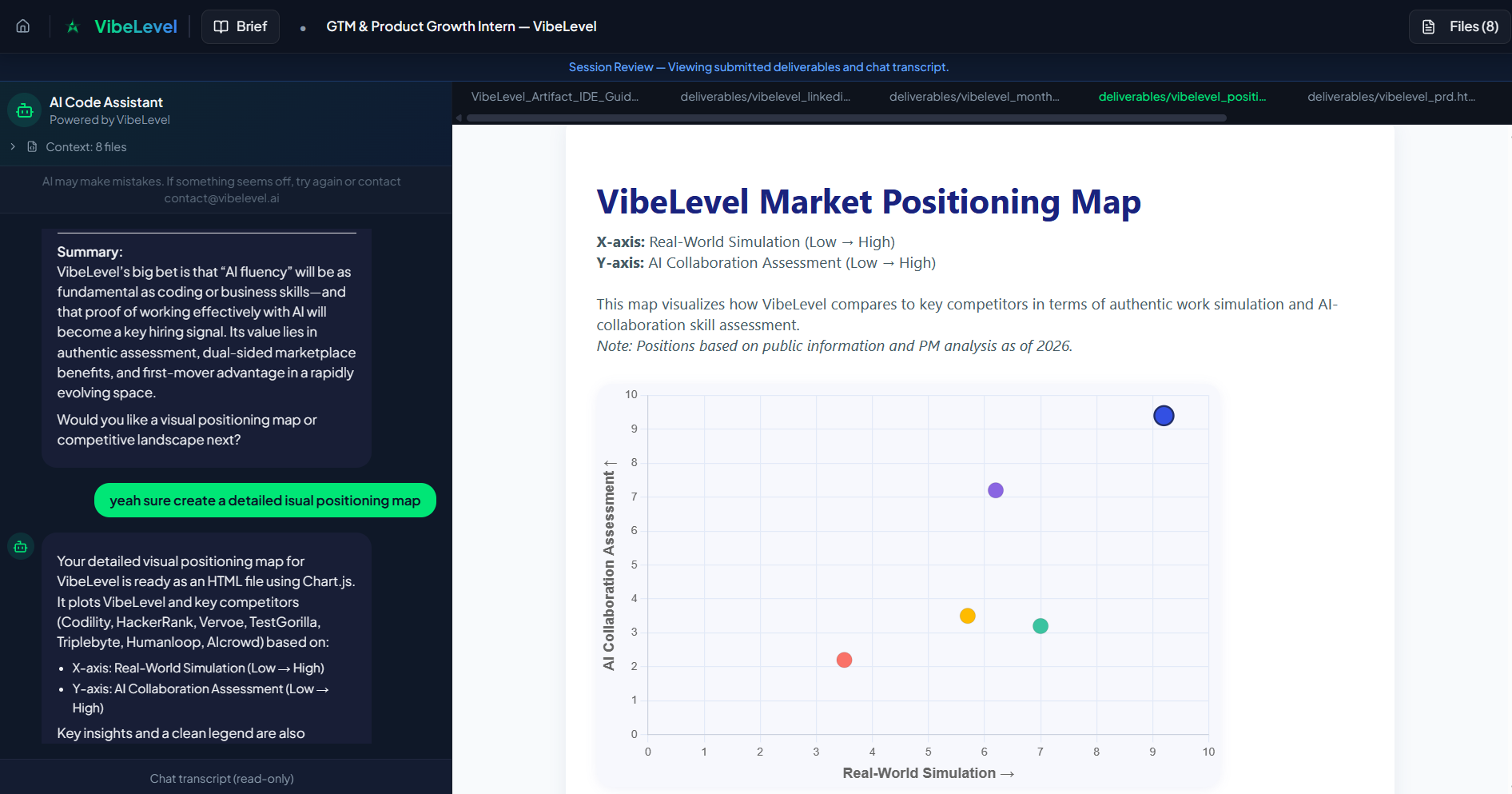
Build artifacts with AI
PRDs · sales emails · CRM responses · support replies · strategy docs. Same scoring engine, role-tuned rubrics.
A real IDE. With a real AI agent. On a real VM.
VibeLevel candidates build the way they actually work — Monaco editor, integrated terminal, file tree, and a Copilot-class AI assistant — not in a stripped-down text box.
Several Agents powering One platform.
Building, assessing, and scoring are all driven by purpose-built agents. They share the same IDE, the same scoring engine, and the same proctoring layer.
Coding Agent
Pairs with the candidate inside the IDE. Edits files, runs commands, helps debug — Copilot-class.
Non-Coding Agent
Same collaboration loop for PMs, sales, support, ops — drafts artifacts and steers iterations.
Claude Code Agent
A first-class third coding agent option — candidates can pick the agent they actually use.
Assessment Builder Agent
Chat-driven assessment creation: gather → design → validate in a real sandbox → publish.
Scoring Agent
Reviews the full session: code, prompts, behavior, artifacts. Outputs multi-dimensional scores + Human Contribution.
Built-in detection for external AI tool use.
Every session is observed by a multi-signal detection layer that flags external AI tool use — ChatGPT, Claude, browser side-panels, automation, and more. Each session ships with a confidence-graded summary so reviewers see the strength of evidence at a glance.
External Assistance Detected — Low Confidence (14 / 100) · 1 signal
Indicators that the candidate may have used external AI tools instead of relying solely on Claude Code, VibeLevel's built-in AI assistant. Higher confidence means stronger evidence.
External Assistance Detected — Medium Confidence (38 / 100) · 2 signals
Indicators that the candidate may have used external AI tools instead of relying solely on Claude Code, VibeLevel's built-in AI assistant. Higher confidence means stronger evidence.
External Assistance Detected — High Confidence (64 / 100) · 3 signals
Indicators that the candidate may have used external AI tools instead of relying solely on Claude Code, VibeLevel's built-in AI assistant. Higher confidence means stronger evidence.
We deliberately don't publish specific detection methods to keep the system honest.
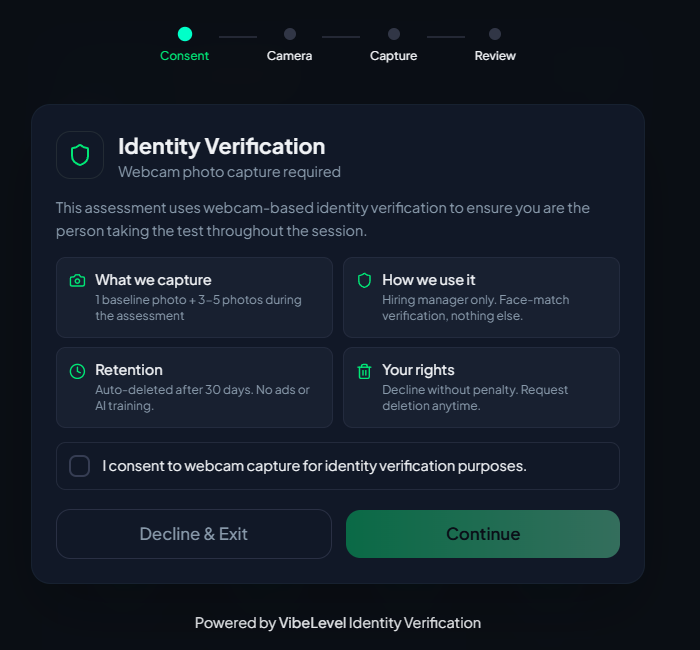
Make sure the right person took the assessment.
Two complementary checks: a live photo capture during the session, and an optional LinkedIn-verified profile. Together they make impersonation expensive and accountability simple.
Live photo capture during the assessment
A baseline photo is captured at the start of the session and verified throughout. Reviewers see the photos and a verified / rejected decision inline with the score report.
Verified profile on every submission
Candidates sign in with LinkedIn; their verified name, photo, and headline are attached to the session. Hiring teams get a real human behind every score, not just an email address.
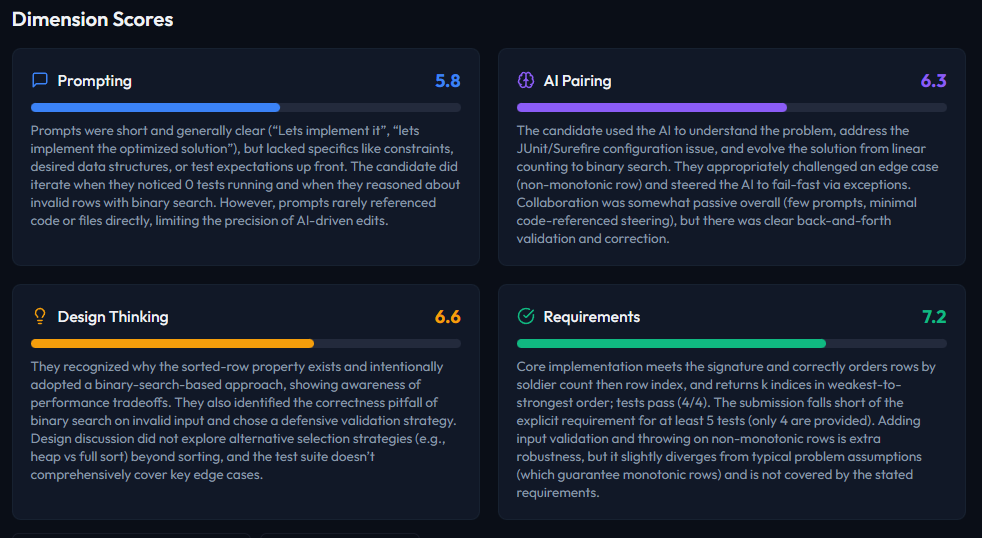
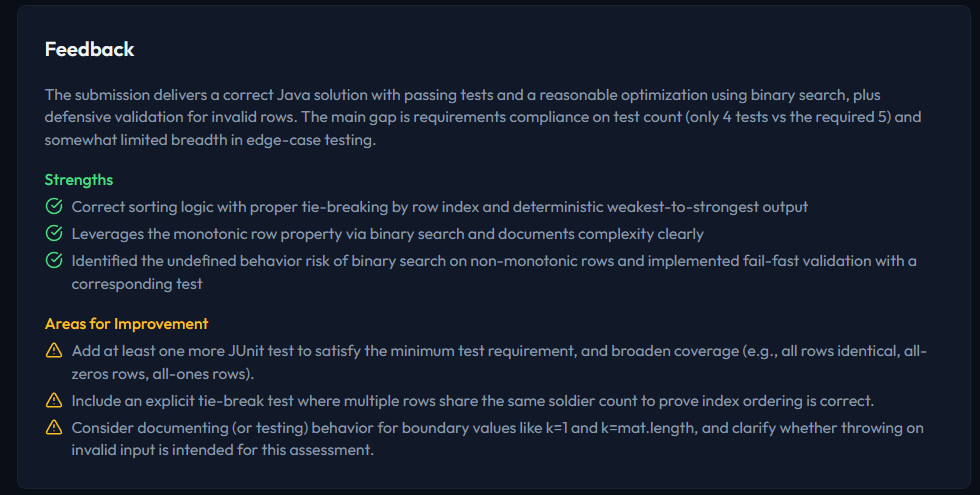
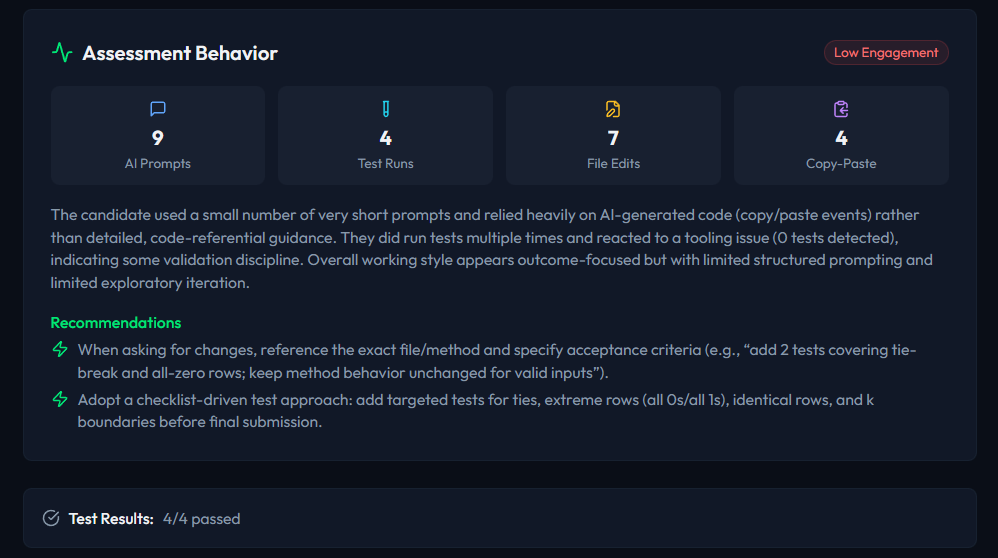
Structured assessment report with multi-dimensional scoring plus a Human Contribution label so it is clear what the candidate did vs. what the AI did.
2–3× more capability at 50% less cost. Structured Assessments with an agentic hiring funnel built in — not bolted on — plus Aura session scoring on the same platform.
| Feature | Others | VibeLevel.ai |
|---|---|---|
| AI Coding Agent (Copilot-class) | ||
| AI Non-Coding Assessments (Claude-class) | ||
| Full IDE (editor, terminal, file tree) | Basic | |
| AI-Native Assessment Scoring | ||
| Human Contribution Detection | ||
| Anti-Cheating & Proctoring Signals | Basic | |
| AI Resume Scoring | ||
| End-to-End Hiring Funnel | ||
| Agentic Auto-Filter & Screening | ||
| Application Forms & Resume Collection | Add-on | |
| Multi-Dimensional Scoring | ||
| Custom AI Agent Persona | ||
| Candidate Comparison & Ranking | Limited | |
| Campus Vibeathons & Talent Pipeline | ||
| Algorithm / LeetCode-style Tests | Supported + AI | |
| Pricing | $300–$500/seat/yr | Pay-as-you-go |
| Free Tier | Limited | Generous |
From 1,000 applicants to 3 finalists.
Pick your path. AI agents run the funnel — you interview only the standouts.